Introducción al análisis de texto
Iván Recalde, ingeniero en sistemas de la UTN, se desempeña actualmente como Data Analyst en el Área de Gestión de Información Estadística en Salud (AGISE) del Ministerio de Salud CABA y hace aquí una introducción muy clara a la visualización y el procesamiento de texto libre usando tidyverse, tidytext, stringr y wordcloud.
Modelo tidy en datos de texto
Los datos no estructurados se definen como datos que no tienen estructura interna identificable. Es un conglomerado masivo y desorganizado de varios objetos que no tienen valor hasta que se identifican y almacenan de manera organizada.
Una vez que se organizan, los elementos que conforman su contenido pueden ser buscados y categorizados (al menos hasta cierto punto) para obtener información.
| detalle |
|---|
| se realizaron 45 observaciones del tipo A en el anio 2017 |
| se realizaron 60 observaciones del tipo B en el anio 2017 |
| se realizaron 23 observaciones del tipo C en el anio 2017 |
| se realizaron 32 observaciones del tipo A en el anio 2018 |
| se realizaron 63 observaciones del tipo B en el anio 2018 |
| se realizaron 19 observaciones del tipo C en el anio 2018 |
Cuando estos están dispuestos de forma tal que variables en las columnas y observaciones en las filas, sin que queden ni filas ni columnas con valores en blanco, podemos decir que se encuentran en formato Tidy y eso ya es un gran avance hacia su procesamiento.
| anio | tipo | n |
|---|---|---|
| 2017 | A | 45 |
| 2017 | B | 60 |
| 2017 | C | 23 |
| 2018 | A | 32 |
| 2018 | B | 63 |
| 2018 | C | 19 |
Este formato nos permite trabajar de manera eficiente y fácilmente acomodable a las funciones de… Sí, tidyverse! Nos permite saber que cada fila va a ser una observación y que no vamos a tener una tabla con infinitas columnas. El problema es que muchas veces los datos de entrada a nuestros scripts/algoritmos no vienen en tidy, sino que los encontramos de la siguiente manera.
| anio | tipo_a | tipo_b | tipo_c |
|---|---|---|---|
| 2017 | 45 | 60 | 23 |
| 2018 | 32 | 63 | 19 |
Así como vimos, el modelo tidy de los datos nos permite manejar de manera mas sencilla y efectiva los datos, incluidos los datos de texto. En este caso para empezar la visualización buscamos que cada fila tenga un solo token: cuando hablamos de token nos referimos a lo que para nuestro problema significa una unidad significativa de texto. En la mayoría de los casos básicos vamos a hablar de token como palabras individuales pero es importante saber que cuando el análisis es más complejo podriamos buscar que nuestros token sean frases o párrafos enteros e intentar identifcar significado de ello.
Tokenizar
¡Arranquemos! Vamos a trabajar con un bello poema de Tamara Grosso, editada por el sello Santos Locos.
# Tamara Grosso @tamaraestaloca cuando todo refugio se vuelve hostil @santoslocospoesia
poema <- c('ADVERTENCIA:',
'No se decirte',
'si todo va a mejorar',
'pero seguro la ficha',
'que te hizo ser quien sos',
'te cayo despues',
'de uno de los peores',
'dias de tu vida')En este caso tenemos un vector de datos en formato character, un primer paso útil sería pasarlo a un data frame, de esta manera lo traemos a un formato con el que estamos mas acostumbradxs a trabajar.
poema_df <- tibble(linea = 1:8, texto = poema)
poema_df## # A tibble: 8 x 2
## linea texto
## <int> <chr>
## 1 1 ADVERTENCIA:
## 2 2 No se decirte
## 3 3 si todo va a mejorar
## 4 4 pero seguro la ficha
## 5 5 que te hizo ser quien sos
## 6 6 te cayo despues
## 7 7 de uno de los peores
## 8 8 dias de tu vidaAhora vamos a usar una funcion para tokenizar nuestro texto. En este caso el analisis lo podriamos pensar sobre palabras por separado, que en principio podrian ser nuestra unidad significativa de texto. ¿Podríamos usar los versos? La funcion que vamos a usar es unnest_tokens() de la biblioteca ‘tidytext’. Su uso más simple es usar los pipes de magrittr para pasarle el data frame como primer parámetro implícito, luego el nombre que queremos que la columna de tokens tenga y por último el nombre de la columna de origen donde deberia buscar el texto a tokenizar.
texto_tokenizado <- poema_df %>%
unnest_tokens(palabra_poema,texto)
texto_tokenizado## # A tibble: 31 x 2
## linea palabra_poema
## <int> <chr>
## 1 1 advertencia
## 2 2 no
## 3 2 se
## 4 2 decirte
## 5 3 si
## 6 3 todo
## 7 3 va
## 8 3 a
## 9 3 mejorar
## 10 4 pero
## # ... with 21 more rowsVeamos poner la lupa en un par de cositas bellas que nos dejo la función. En principio vemos que cada palabra quedo en una fila, estaríamos ahora en condiciones de afirmar que cada observacion está contenida en un registro diferente. Luego vemos que para facilitar el manejo nos transformó todos los tokens a minusúculas; en el caso de no querer esto, podemos pasarle a la funcion como parametro to_lower = FALSE de la siguiente manera.
poema_df %>%
unnest_tokens(palabra_poema,texto, to_lower = FALSE)## # A tibble: 31 x 2
## linea palabra_poema
## <int> <chr>
## 1 1 ADVERTENCIA
## 2 2 No
## 3 2 se
## 4 2 decirte
## 5 3 si
## 6 3 todo
## 7 3 va
## 8 3 a
## 9 3 mejorar
## 10 4 pero
## # ... with 21 more rowsCompletemos un circuito basico de analisis y armemos unas visualizaciones
Vamos entonces a imaginar que tenemos varios textos consecutivos (poemas en nuestro caso) para hacer un poco más divertido el análisis.
varios_poemas <- poema_df %>%
bind_rows(poema2_df, poema3_df, poema4_df)## # A tibble: 23 x 1
## texto
## <chr>
## 1 ADVERTENCIA:
## 2 No se decirte
## 3 si todo va a mejorar
## 4 pero seguro la ficha
## 5 que te hizo ser quien sos
## 6 te cayo despues
## 7 de uno de los peores
## 8 dias de tu vida
## 9 ENTRE NOSOTROS:
## 10 Quisiera saber si alguna vez
## # ... with 13 more rowsVamos de nuevo a tokenizar este df, como ya habíamos visto anteriormente y vamos a proceder a armar una visualizacion. Usaremos count() para que nos cuente cuantas ocurrencia de cada token hay, simplemente debemos decirle en qué columna se encuentra lo que queremos cuantificar. Usamos la funcion reorder(), para que luego el gráfico nos muestre las barras ordenadas. Por último usaremos ggplot2.
library(ggplot2)
varios_poemas_tokenizados <- varios_poemas %>%
unnest_tokens(palabra_poema,texto)
varios_poemas_tokenizados%>%
count(palabra_poema) %>%
filter(n > 1) %>%
mutate(palabra_poema = reorder(palabra_poema, n)) %>%
ggplot(aes(palabra_poema, n)) +
geom_col() +
coord_flip()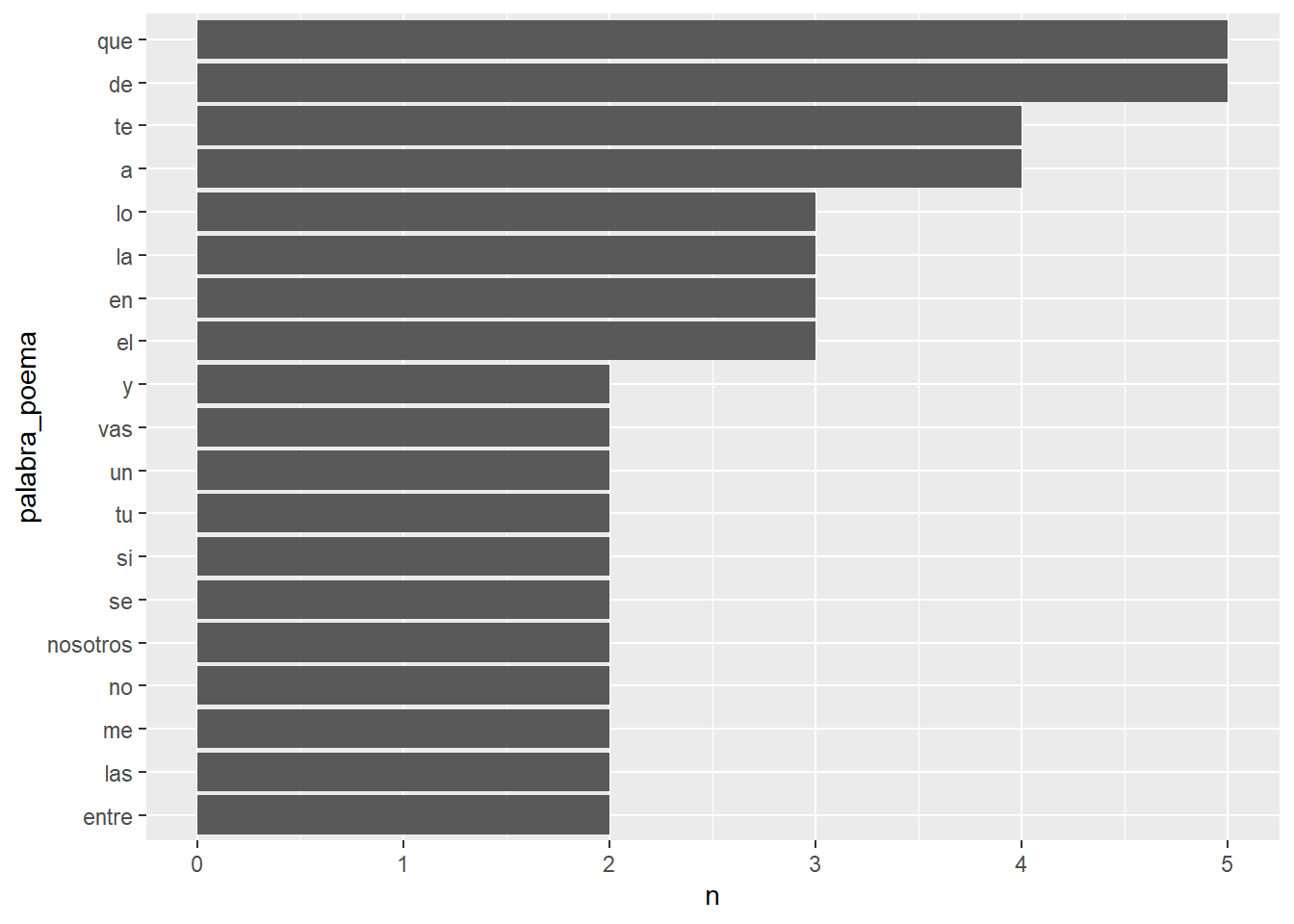
Otra biblioteca bastante útil para visualizar de manera rápida ocurrencia de tokens (palabras) es wordcloud. Vamos a usar la funcion de base with(), para poder aplicarlo en nuestro formato con pipes de magrittr. Tenemos que tener cuidado que por defecto la mínima frecuencia de aparicion es 3.
library(wordcloud)
varios_poemas_tokenizados %>%
# filter(!palabra_poema %in% stopwords::stopwords(language = 'spanish')) %>%
count(palabra_poema) %>%
with(wordcloud(palabra_poema, n,min.freq = 0))
Como vemos hay una linea comentada, que es un antijoin con stop_words, pero, ¿qué son stop_words?
## [1] "de" "la" "que" "el" "en" "y" "a" "los" "del" "se"
## [11] "las" "por" "un" "para" "con" "no" "una" "su" "al" "lo"
## [21] "como" "más" "pero" "sus" "le"Se trata un vector de palabras típicas usadas en algún lenguaje que le pasemos por parametro, pero que no aportan significado al texto en la mayoria de las ocasiones. Esto sirve para que las palabras con más ocurrencias no sean siempre las mismas sino que sean palabras significativas que aporten valor del mensaje. No lo usamos porque nuestro ejemplo tenia una cantidad muy baja de palabras y haberlo usado hubiese eliminado casi todas las palabras con mas de una ocurrencia como vemos abajo. Lo importante de todas formas es tener presente la existencia de estas colecciones de palabras.
library(wordcloud)
varios_poemas_tokenizados %>%
filter(!palabra_poema %in% stopwords::stopwords(language = 'spanish')) %>%
count(palabra_poema) %>%
with(wordcloud(palabra_poema, n,min.freq = 0))
Stringr
En este punto vamos a presentar otra herramienta muy potente llamada stringr. Este paquete nos propociona un conjunto de funciones para recuperar de manera sencilla informacion de texto. Esta está construida sobre stringi, otra biblioteca mas extensa. Para explotar más su uso y si se quedan con ganas, siempre es buena idea explorar el cheatsheet que tiene.
https://rstudio.com/resources/cheatsheets/
Vamos entonces a ver un vistazo por algunas funciones. Comencemos con algo simple, contemos cuántos caracteres tiene cada verso.
library(stringr)
poema_df %>%
mutate(cantidad_caracteres = str_count(texto)) ## # A tibble: 8 x 3
## linea texto cantidad_caracteres
## <int> <chr> <int>
## 1 1 ADVERTENCIA: 12
## 2 2 No se decirte 13
## 3 3 si todo va a mejorar 20
## 4 4 pero seguro la ficha 20
## 5 5 que te hizo ser quien sos 25
## 6 6 te cayo despues 15
## 7 7 de uno de los peores 20
## 8 8 dias de tu vida 15Quedemonos ahora solo con una parte del texto, en este caso los primeros 5 caracteres. Veamos que a nivel gráfico nos muestra el resultado con comillas para denotar que quedó un espacio [‘’], al principio o al final.
poema_df %>%
mutate(solo_primeros_cinco = str_sub(texto,1,5)) ## # A tibble: 8 x 3
## linea texto solo_primeros_cinco
## <int> <chr> <chr>
## 1 1 ADVERTENCIA: ADVER
## 2 2 No se decirte No se
## 3 3 si todo va a mejorar si to
## 4 4 pero seguro la ficha "pero "
## 5 5 que te hizo ser quien sos que t
## 6 6 te cayo despues te ca
## 7 7 de uno de los peores de un
## 8 8 dias de tu vida "dias "Las posiciones son relativas al largo del texto, podemos entonces decirle que tome los últimos 5 caracteres de la siguiente manera
poema_df %>%
mutate(solo_primeros_cinco = str_sub(texto,-5,-1)) ## # A tibble: 8 x 3
## linea texto solo_primeros_cinco
## <int> <chr> <chr>
## 1 1 ADVERTENCIA: NCIA:
## 2 2 No se decirte cirte
## 3 3 si todo va a mejorar jorar
## 4 4 pero seguro la ficha ficha
## 5 5 que te hizo ser quien sos n sos
## 6 6 te cayo despues spues
## 7 7 de uno de los peores eores
## 8 8 dias de tu vida " vida"Otro uso tipico es querer modificar todo a minusculas, pero como sobre gustos no hay nada definido también podríamos modificar todo a mayusculas.
poema_df %>%
mutate(mayusculas = str_to_upper(texto),
minusculas = str_to_lower(texto)) ## # A tibble: 8 x 4
## linea texto mayusculas minusculas
## <int> <chr> <chr> <chr>
## 1 1 ADVERTENCIA: ADVERTENCIA: advertencia:
## 2 2 No se decirte NO SE DECIRTE no se decirte
## 3 3 si todo va a mejorar SI TODO VA A MEJORAR si todo va a mejorar
## 4 4 pero seguro la ficha PERO SEGURO LA FICHA pero seguro la ficha
## 5 5 que te hizo ser quie~ QUE TE HIZO SER QUIEN~ que te hizo ser quien~
## 6 6 te cayo despues TE CAYO DESPUES te cayo despues
## 7 7 de uno de los peores DE UNO DE LOS PEORES de uno de los peores
## 8 8 dias de tu vida DIAS DE TU VIDA dias de tu vidastr_detect()
Veamos ahora como identificar patrones dentro del texto libre desde su manera mas sencilla y veamos algunos ejemplos que pueden servir como disparadores. Generemos una columna nueva que nos diga si este patron estaba en el texto de cada registro.
poema_df %>%
mutate(tengo_de = str_detect(texto, 'de')) ## # A tibble: 8 x 3
## linea texto tengo_de
## <int> <chr> <lgl>
## 1 1 ADVERTENCIA: FALSE
## 2 2 No se decirte TRUE
## 3 3 si todo va a mejorar FALSE
## 4 4 pero seguro la ficha FALSE
## 5 5 que te hizo ser quien sos FALSE
## 6 6 te cayo despues TRUE
## 7 7 de uno de los peores TRUE
## 8 8 dias de tu vida TRUEPodriamos tambien querer filtrar y quedarnos solo con las ocurrencias de este patron.
poema_df %>%
filter(str_detect(texto, 'de')) ## # A tibble: 4 x 2
## linea texto
## <int> <chr>
## 1 2 No se decirte
## 2 6 te cayo despues
## 3 7 de uno de los peores
## 4 8 dias de tu vidaVolvamos ahora al caso donde teniamos todos los poemas juntos, ¿sería posible identificar de alguna manera cada poema por separado?
## # A tibble: 23 x 1
## texto
## <chr>
## 1 ADVERTENCIA:
## 2 No se decirte
## 3 si todo va a mejorar
## 4 pero seguro la ficha
## 5 que te hizo ser quien sos
## 6 te cayo despues
## 7 de uno de los peores
## 8 dias de tu vida
## 9 ENTRE NOSOTROS:
## 10 Quisiera saber si alguna vez
## # ... with 13 more rowsBusquemos entonces generar un corte cada vez que encuentre los ‘:’, que es en este caso por lo menos lo que nos indica que hay un titulo. Una funcion que nos podria servir es cumsum(), que nos va a mantener un contador como suma acumulada cada vez que se cumpla una condicion que le pasemos por parametro.
poemas_separados <- varios_poemas %>%
mutate(poema = cumsum(str_detect(texto, ':')))
poemas_separados## # A tibble: 23 x 2
## texto poema
## <chr> <int>
## 1 ADVERTENCIA: 1
## 2 No se decirte 1
## 3 si todo va a mejorar 1
## 4 pero seguro la ficha 1
## 5 que te hizo ser quien sos 1
## 6 te cayo despues 1
## 7 de uno de los peores 1
## 8 dias de tu vida 1
## 9 ENTRE NOSOTROS: 2
## 10 Quisiera saber si alguna vez 2
## # ... with 13 more rowsExcelente, esto nos permitirá abstraernos de la cantidad de registros que tengamos tokenizados por cada archivo de texto original.
Como recuperar lo que partimos? [lo rompi?]
Una vez que aprendimos a separar [romper] algo, estaría buenisimo tambien saber volverlo a armar, ¿verdad? Vamos a usar la funcion paste() y le vamos a pasar por parametro collapse, para definirle que queremos qué nos deje en el medio de cada verso del poema en este caso.
poemas_unidos <- poemas_separados %>%
group_by(poema) %>%
mutate(poema_entero = paste(texto,
collapse = ' ')) %>%
slice(1) %>%
ungroup() %>%
select(poema_entero)
poemas_unidos## # A tibble: 4 x 1
## poema_entero
## <chr>
## 1 ADVERTENCIA: No se decirte si todo va a mejorar pero seguro la ficha que~
## 2 ENTRE NOSOTROS: Quisiera saber si alguna vez se van a poder leer las men~
## 3 LOOP: Todavía me parece Que vas a venir un día Y me vas a decir lo que y~
## 4 VARIACIONES SOBRE LA TRISTEZA: Meter la mano en el cajón de las aspirina~Proximos pasos -> str_extract() y regex()
Para ir finalizando con estas herramientas baáicas, volvamos al ejemplo original que usamos para ver como podíamos encontrarnos la informacion no estructurada
| detalle |
|---|
| se realizaron 45 observaciones del tipo A en el anio 2017 |
| se realizaron 60 observaciones del tipo B en el anio 2017 |
| se realizaron 23 observaciones del tipo C en el anio 2017 |
| se realizaron 32 observaciones del tipo A en el anio 2018 |
| se realizaron 63 observaciones del tipo B en el anio 2018 |
| se realizaron 19 observaciones del tipo C en el anio 2018 |
Vamos a usar str_extract para obtener la informacion que esta perdida dentro del campo libre, pero para que esta función realmente explote su potencia va a necesitar que le agreguemos expresiones regulares. Las expresiones pueden ir desde algo muy simple, hasta algo super complejo, podemos ayudarnos del cheatsheet y de paginas como https://regex101.com/ que nos permiten en tiempo real ir probando nuestras expresiones. Vamos a ver como a priori este caso se resuelve con expresiones bastante amigables
tabla_valores_no_estructurada %>%
mutate(n = str_extract(detalle, regex('[0-9]+')), #uno o mas numeros
tipo = str_extract(detalle, regex('[ABC] ')), #letras en mayuscula A, B o C
anio = str_extract(detalle, regex('[0-9]+$'))) #uno o mas numeros y fin de texto## # A tibble: 6 x 4
## detalle n tipo anio
## <chr> <chr> <chr> <chr>
## 1 se realizaron 45 observaciones del tipo A en el anio 2~ 45 "A " 2017
## 2 se realizaron 60 observaciones del tipo B en el anio 2~ 60 "B " 2017
## 3 se realizaron 23 observaciones del tipo C en el anio 2~ 23 "C " 2017
## 4 se realizaron 32 observaciones del tipo A en el anio 2~ 32 "A " 2018
## 5 se realizaron 63 observaciones del tipo B en el anio 2~ 63 "B " 2018
## 6 se realizaron 19 observaciones del tipo C en el anio 2~ 19 "C " 2018Algo interesante a tener en cuenta es observar como la primera expresión regular no trae el año además del n. Esto se debe a que salvo que le indiquemos lo contrario str_extract(), nos trae solo lo primero que encuentra. Entonces una vez que encuentra uno o mas numeros seguidos, deja de mirar el texto.
Conclusion
Este pequeño tutorial tiene como finalidad presentar un vistazo rapido por bastantes herramientas para el analisis de texto. ¡Ojalá sirva como disparador para investigar más!